
编译时的第一步是词法分析,该部分的主要功能是将输入的代码分为若干独立的单词,便于后续的处理步骤。这里所说的独立单词包括关键字、标识符、常数、运算符和界符,词法分析结束后将得到一串单词流,每个单词是一个二元式(种类,属性),属性中一般存储常数或标识符的值,为了便于存储常数和标识符的具体值会被存在常数表和标识符表中,二元组中仅存储指向表的索引。
在词法分析之前,会将代码中的注释先去除,我采取的策略是将注释全部转为空格,这样可以避免移动后续的字符其保留了后续单词在源文件中的实际位置。然后就会使用确定有限自动机(DFA)来扫描单词。
DFA接受一定的输入字符,便确定地转移到一个状态,到达终止状态时便接受了之前输入的若干字符。在利用DFA扫描单词时,逐一读入字符让DFA进行状态转移,下图为一个词法分析器DFA参考图: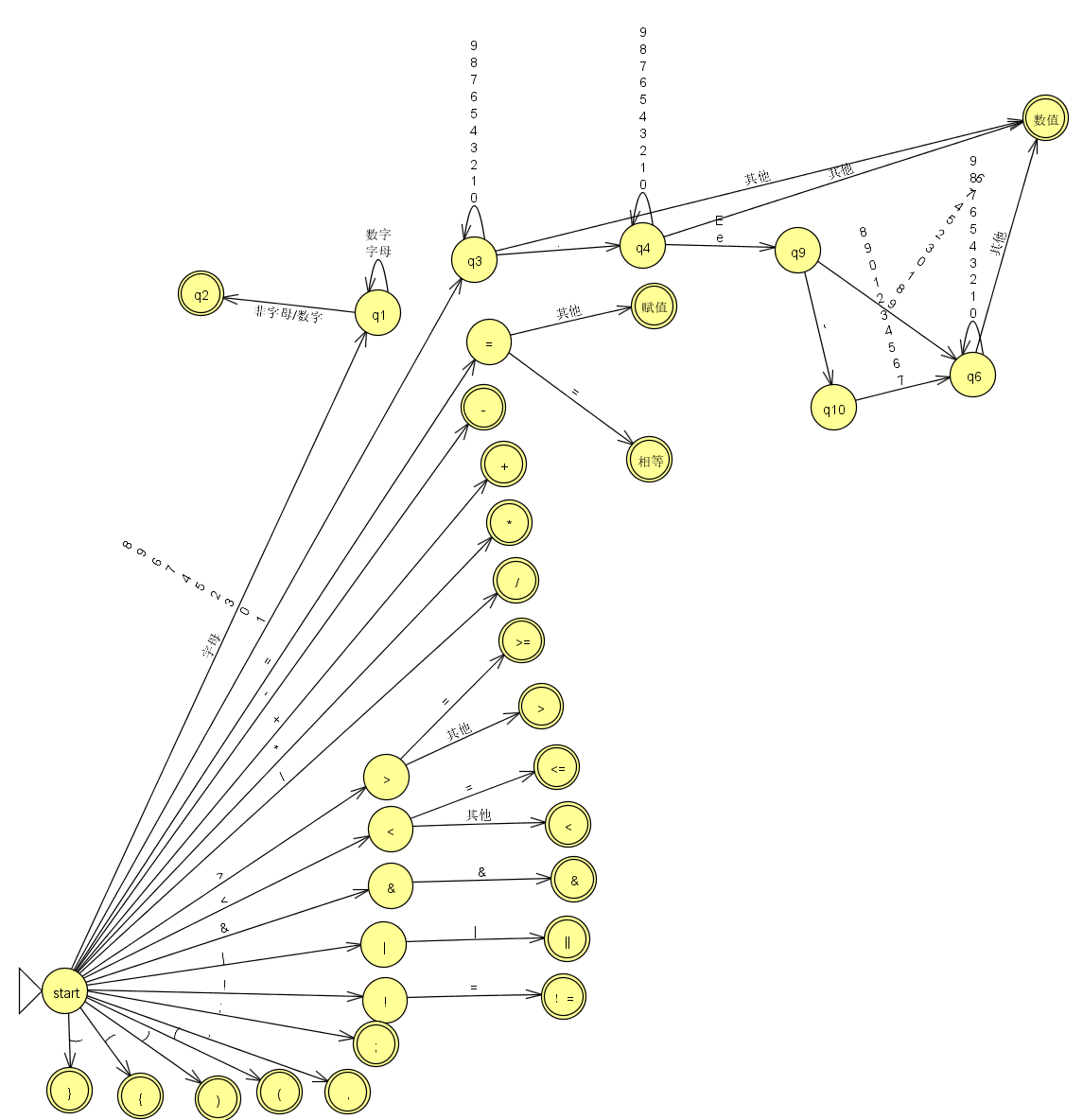
同时为避免一次性读入过多数据而使用缓冲区,缓冲区被平均分成两个部分,扫描时仅会扫描其中一部分,当扫描完毕且上次读入的数据填满了当前部分(说明可能还有后续数据),就会再读数据填入另一部分缓冲区,两块缓冲区交替使用。
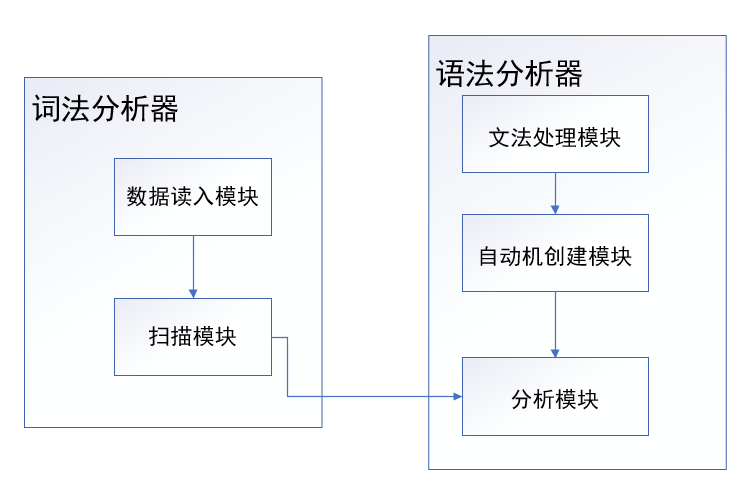
语法分析中有自上而下分析方法和自下而上分析方法,项目中使用的是LR(1)自下而上分析方法,核心思想是将输入串归约到文法的开始符号。这里将不会详细叙述LR(1)的原理,我主要讲述项目中如何实现LR(1)进行语法分析,下图是词法分析与语法分析的顶层设计。
首先是文法和数据结构的定义,文法可以保存在外部的文本文件中,程序运行时动态读入。为了将读入的文法转化为一定的结构,方便后续的处理,使用 Symbol 类表示文法中的符号(包括终结符和非终结符),为了表示产生式,Symbol 类中使用vector 存储当前终结符的所有产生式,vector 中每个元素又是一个 vector,按顺序存储了产生式中每一个符号,符号以指针的形式存储,可方便在各个产生式间跳转。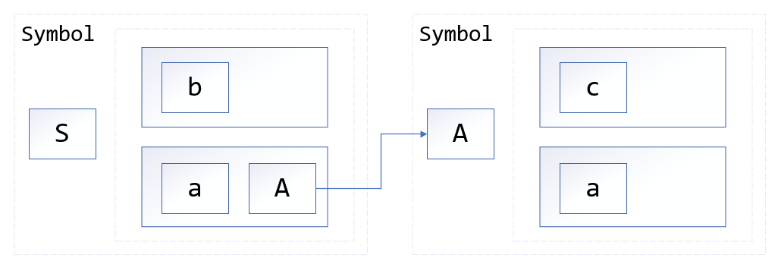 上图显示了产生式S->b|aA、A->c|a的结构。在这个基础上,Grammer类中,管理了所有终结符和非终结符,并负责计算每个非终结符的FIRST 集合。
上图显示了产生式S->b|aA、A->c|a的结构。在这个基础上,Grammer类中,管理了所有终结符和非终结符,并负责计算每个非终结符的FIRST 集合。
文法处理完毕后就需要构建自动机,构建出项目集和有限自动机,为了表示项目、自动机,需要抽象出相关的类。考虑到项目Item类中要储存产生式,增加产生式Production类,Item类中要存储展望的符号和圆点位置,Production类中不实际存储产生式,只存指针。
第一步是定义文法,文法就规定了所要实现的语法规则,我选择实现的有变量定义、函数定义与调用、逻辑表达式、运算表达式、if-else语句、while语句等,具体查看文法文件中的定义,为了方便处理,一个符号的所有产生式都统一写在一行。
第二步是读入文法并做处理,读入文法并将其存入到上述的数据结构中,这段过程中需要维护符号表、左侧非终结符表、字符串与Symbol映射关系,注意在最后加入#符号即可。接下来计算哪些非终结符是可空的,这是后面计算FIRST集合的前置工作,遍历所有左侧非终结符,对于每个左侧非终结符遍历其所有产生式,如果存在产生式为空则该非终结符可空,否则就是不存在明显的空,需要遍历产生式中每个符号,若每个符号都可为空那么该非终结符可空,上述步骤需要反复执行,直到可空集合大小不再变化。处理的最后一步就是计算FIRST集合,遍历所有左侧非终结符,对于每个左侧非终结符遍历其所有产生式以计算FIRST集,对于每个产生式遍历其符号,如果是终结符就可以直接加进FIRST集合,如果是非终结符首先看其FIRST集是否已经计算出来,若已计算出来则将其加入当前要算的左侧非终结符的FIRST集,这时就判断这个非终结符是否可空,若可空则可继续遍历产生式下一个符号,否则跳出循环遍历下一个产生式,计算左侧非终结符的FIRST集的操作需反复执行,直到FIRST集合不再变化。
第三步构建自动机和LR(1)分析表,首先准备好计算closure集合的函数,这个函数接受一个状态,遍历状态内的所有项目,假设遇到项目形如A->α·Bβ, b,那么就求βb的FIRST集,将FIRST集中的所有符号都作为B的每个产生式的前瞻,得到的项目都加入到当前状态中,重复上述操作直到当前状态不再变化。接着就可以创建自动机,从初始状态开始,用所有符号试探是否可以发生转移,若可发生转移且新状态不存在,则创建状态并求其closure集,在这个过程中就能记录下转移的关系。最后就是创建LR(1)分析表,在已经得到自动机的基础上,根据转移关系和每个项目的内容就可填写分析表,项目的点位于产生式末尾就要执行规约,项目的点位于产生式中间就要执行移入。
第四步开始语法分析,有了之前的铺垫,这一步就比较简单了,创建好符号栈和状态栈,不断读入单词,按照分析表来执行动作就可以完成语法分析。



